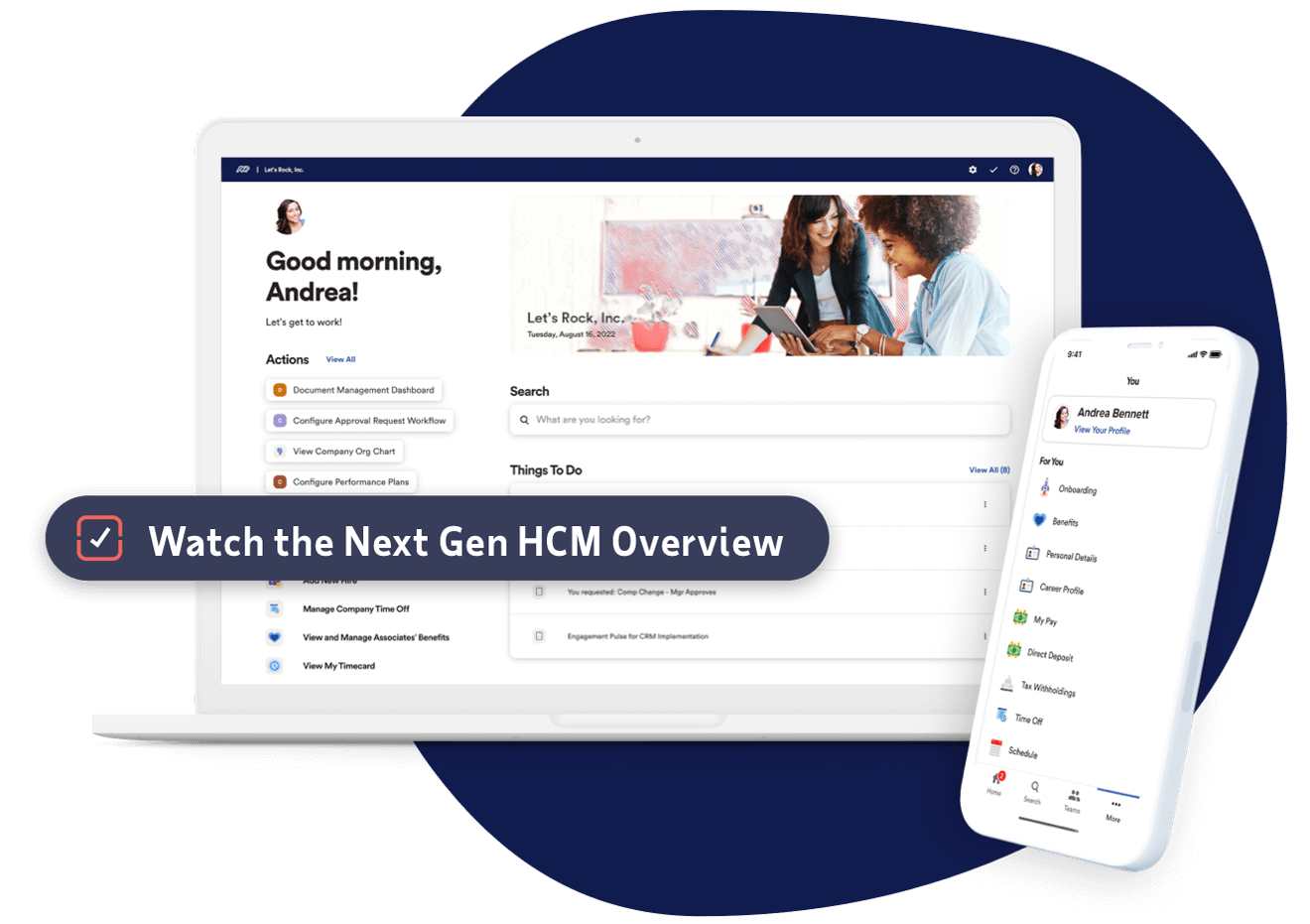
Our next generation HCM platform is designed for how people really work today — and its scalable model is built to keep you successful tomorrow.
What makes Next Gen HCM different
Empowering experiences to everyone, trusted insights and guidance for informed decisions, and adaptable technology so your organization can continuously evolve.

ADP's Next Gen HCM is designed for how teams work — helping you break down silos, improve engagement and performance, and create a culture of connection.
Data-driven insights in the flow of work can help executives and team leaders make better decisions.


Seize new business opportunities with a global tech platform designed to rapidly adapt, scale and add new capabilities to support your changing needs.
ADP Next Gen HCM Capabilities
Modern, personalized tools to help everyone in your organization quickly and confidently do their best work.
 Core HR
Core HR
 Global Payroll
Global Payroll
 Connected Talent
Connected Talent
 Workforce Management
Workforce Management
 Benefits and Wellness
Benefits and Wellness
 Analytics and Benchmarking
Analytics and Benchmarking

Built from the ground up to be a global, flexible platform to support teams and team leaders.

Simplifies and helps ensure accurate sourcing, managing, and delivery of payroll services in multiple currencies for global employee populations.

Recruit and activate talent by enabling managers to invigorate, inform and inspire their teams.

Effectively manage workers' time — and time off — while improving productivity by gaining insight into scheduling dynamics and cost of labor.
Organizations with automated scheduling report nearly 2x greater increase in revenue per employee than those that don't automate.2

Reduce the benefits administration workload, improve employee engagement, and increase plan adoption.
Every year for the past five years, about one-third of organizations have increased their benefits offerings. As a result, the average organization now offers more than 20 distinct benefits.3

Insights derived globally from
See what other people are saying about Next Gen HCM
It has been a game-changer for our organization. It is intuitive. Our employees find it very easy to use. We're so excited about the data management opportunities and the implementation process couldn't have been smoother.
Jane Luers Vice President of Human Resources, Opaa! Food Management

ADP's product allows us to take a look at an organization as a set of teams, which is the way people really work.
Tonjia Oglesby VP of Human Resources, AEG Vision

For those of us in HR that had to set up open enrollment, the benefits experience was a godsend. To be able to work with a platform that can apply our business rules for life events or how much one can enroll in voluntary life insurance based on multipliers - the system can handle whatever we throw at it.
Libby McCartheigh Total Rewards Director, The Scoular Company


The adaptable HCM solution for how people really work
Empower your employees. Make better decisions. Confidently embrace change.

Josh Bersin weighs in: Next Gen HCM has arrived
Industry expert Josh Bersin discusses the top features for HCM systems and how ADP Next Gen HCM delivers.

Adaptable technology platform
The potential of your organization is limited by the capabilities of your technology.

Global compliance
A single, global system of record with compliance built into system configuration.

Schedule a discovery call
Speak with an ADP associate to discuss your needs and challenges
and determine the right solution for you.
Your privacy is assured.
Any features, functionality or services referenced in ADP's sales or marketing materials are subject to change in scope or timing at ADP's discretion.
¹ ADP Research Institute: Evolution of Pay Report, 2019
² Aptitude Research Partners, June 2020
³ Know Which Benefits Your Employees Care About, Gartner 2020


